

どうも、イソップです。
DOMについての連載第3回目です。
今回からは、実際にDOMを取得する方法について触れていきたいと思います。
DOMの取得
今まで紹介してきたように、DOMとしてHTMLの要素をツリー構造にすると、Documentオブジェクトが一番上にありました。
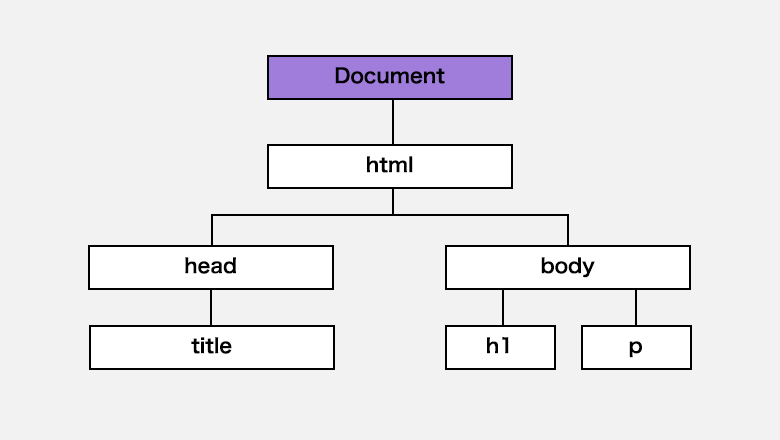
DOMを操作するのは、始めにDocumentオブジェクトが全てを担います。
取得する場合も、Documentオブジェクトのメソッドを使うことでDOMを検索して、該当のノード(要素)を取得します。
ちなみに、主なものを挙げると、次のようなものがあります。
- document.getElementById
- document.getElementsByTagName
- document.getElementsByClassName
- document.querySelector
- document.querySelectorAll
IDで取得する
HTMLでのIDはご存知でしょうか?
要素それぞれのid属性に名前が設定できます。
idに指定できる名前は、ページの中では一意ではなければいけません。
特定のDOMの取得では、HTML要素のidを指定する getElementById メソッドを使用します。
例えば、idが page の要素を取得したい場合は、次のように記述します。
var page = document.getElementById('page');
これで、idが page の要素を取得できます。
実際に返されるのは、Elementオブジェクトになります。
このメソッドは、1つの要素を検索するため、他の取得メソッドに比べて処理が早いのが特徴です。
パフォーマンスを重視するのであれば、積極的に使いましょう。
また、くれぐれもIDの指定は一意にしてください。
同じIDが2つ以上あると、思わぬバグが発生することになりかねません。
タグ名で取得する
タグ名での取得は、getElementsByTagName メソッドを使用します。
ページ中にある、指定されたタグ全てを取得します。
例えば、ページ全体のpタグを取得するには、次のように記述します。
var paragraph = document.getElementsByTagName('p');
pタグが取得されると、NodeListオブジェクトが返されます。
NodeListとは、配列のような、ノードの集合体のオブジェクトです。
getElementsByTagName メソッドの便利なところは、Documentオブジェクトからではなく、
Elementオブジェクトからも、実行できるところです。
つまり、getElementById で取得したElementオブジェクトから、
さらに getElementsByTagName を使用してDOMを検索することが出来ます。
<div id="page">
<p>foo</p>
<p>bar</p>
<p>baz</p>
</div>
<p>abc</p>
<p>def</p>
<script>
var page = document.getElementById('page');
// id="page" 内のpタグを取得
var pageParagraph = page.getElementsByTagName('p');
console.log(pageParagraph.length); // 3
// ページ全体のpタグを取得
var paragraph = document.getElementsByTagName('p');
console.log(paragraph.length); // 5
</script>
このように、Elementオブジェクトから検索することで、Documentオブジェクトからよりもはるかに効率的な処理が可能になります。
ちなみに、Elementオブジェクトから getElementById を使用することは出来ません。
page.getElementById('something'); // エラー
また、ここで注意したいのは、メソッド名がgetElement「s」ByTagNameで、複数形のところです。
このsが抜けていてハマったことは数知れず。。 このメソッドでは複数個取得する点を理解しておきましょう。
ライブオブジェクトという性質
getElementsByTagName で取得された要素はNodeListとして返されます。
このNodeListは動的な参照を持っています。
<div id="page">
<p>foo</p>
<p>bar</p>
</div>
<script>
var pageParagraph = document.getElementsByTagName('p');
var paragraph = document.getElementsByTagName('p');
console.log(paragraph.length); // 2 ①
var newParagraph = document.createElement('p'); // ②
newParagraph.appendChild(document.createTextNode('baz'));
var page = document.getElementById('page');
page.appendChild(newParagraph); // ③
console.log(paragraph.length); // 3 ④
</script>
まず、全体のpタグを取得します。(①) この時点での要素の数は2です。
次に、新しくpタグを作成(createElement)します。(②)
作成された要素を id="page" の中に追加します。(③)
この時点での要素の数は3となっています。(④)
つまりこれからわかることは、一度取得したNodeListオブジェクトは変数に格納されたとしても、
常にDOMツリーへの参照を持っている、ということになります。
これをライブオブジェクトと呼びます。
常にDOMツリーを参照しているので、要素の数が増えたり減ったりしても、再取得する必要がないということですね。
ただし、注意点もあります。
この性質を理解していないと、forループで各要素に子要素を追加したい場合などでは、無限ループになってしまいます。
var paragraph = document.getElementsByTagName('p');
for (var i = 0; i < paragraph.length; i++) {
paragraph[i].appendChild(document.createElement('span')); // 無限ループ
}
この回避策は、paragraphのlengthをあらかじめ保存しておくことで回避できます。
var paragraph = document.getElementsByTagName('p');
for (var i = 0, l = paragraph.length; i < l; i++) { // lengthを変数に保存する
paragraph[i].appendChild(document.createElement('span'));
}
だんだんDOMマスターに近づいてきましたね。
次回に続きます。
